こんにちは、人です。
今回は第二回として、畳み込みニューラルネットワークを理解していきましょう!
いわゆるCNN(Convolutional Neural Network)ってやつですね〜
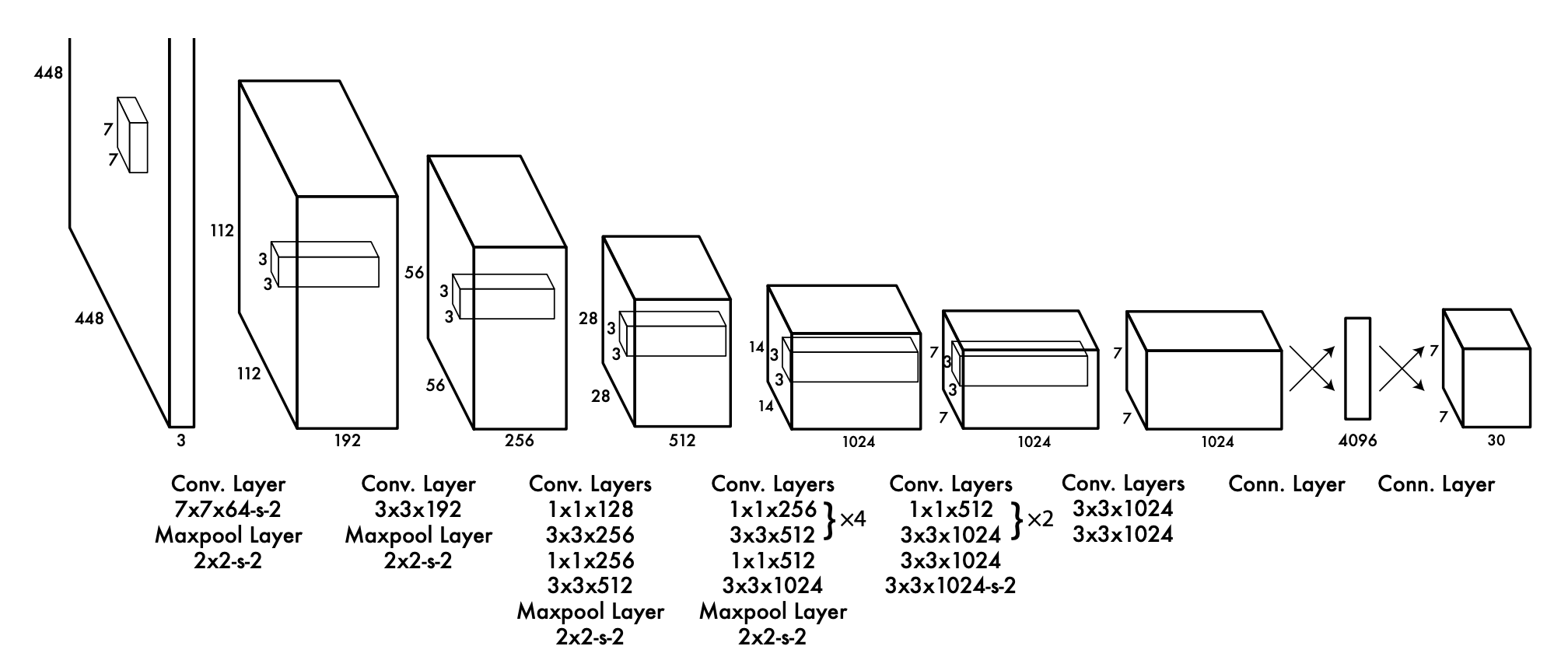
それでは早速YOLOの論文に書かれていた図を見ていきます。👇
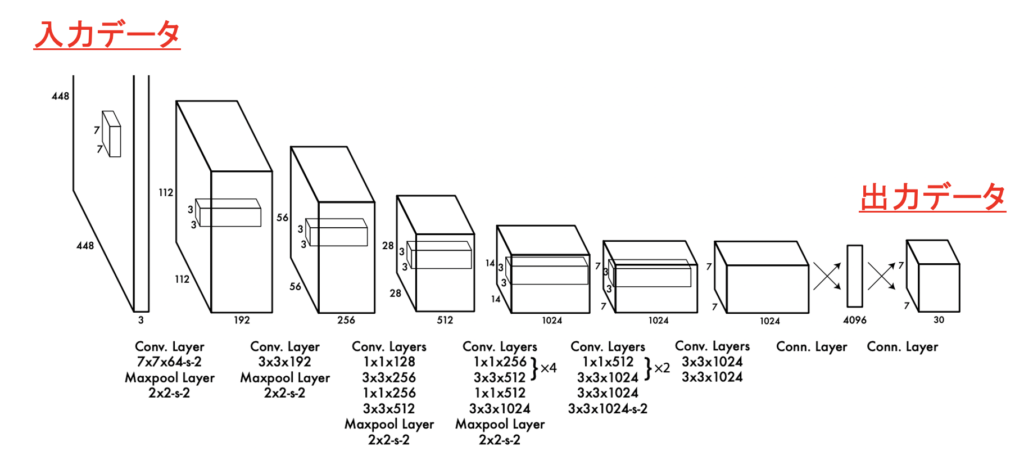
今回は分かりやすいように、「入力データ」、「出力データ」にはどんな値が入っているのか、また、その他「Conv. Layer」, 「Maxpool Layer」, 「Conn. Layer」は何を表しているのか。について説明していこうと思います!
入力データ
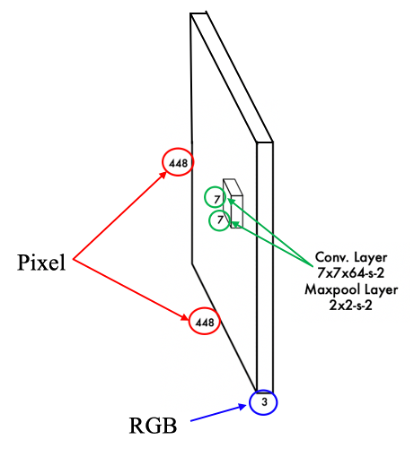
上に説明図を載せておきました。👆
まぁ、大体予想はついていたかもしれませんが、図中の「448」という数値はpixel数を表しています。
ただ、当然様々なサイズの画像が入力されますから、ここでは448×448にリサイズされるということだと思います。
次に図中の「3」という数値を見ていきましょう!これは画像がRGBで構成されていることを示しています。
以下の図をご覧ください。👇
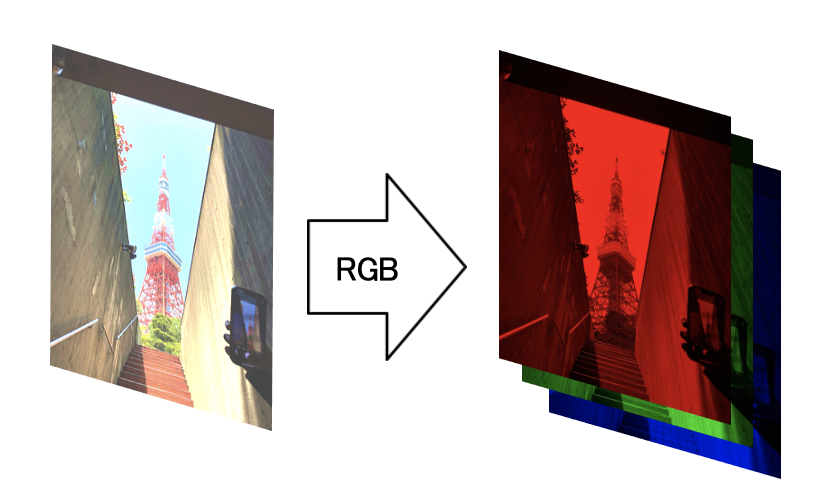
左の図が入力図だとすると、赤色の濃さ画像、緑の濃さ画像、青の濃さ画像に分けられるということです。
次に図中の「7」という数値に注目していきます。
Conv. Layerとありますが、これはConvolutional Layerの略です。次の節で詳しく解説します!
Conv. Layer
これはつまり畳み込み処理ですね。
例えば「1」と書かれた画像が入力されたとします。
これは白黒の濃淡で表されるので「0=白」、「255=黒」として以下の画像のようになります。
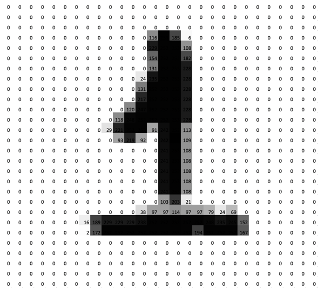
これを少し簡略化させてもらって5×5の2値画像で表すと以下のようになります。
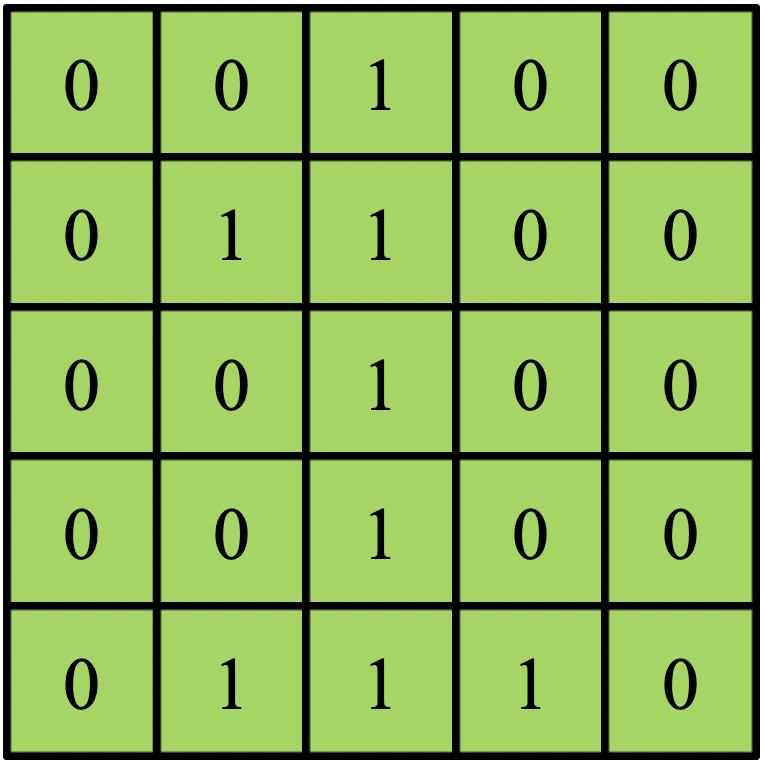
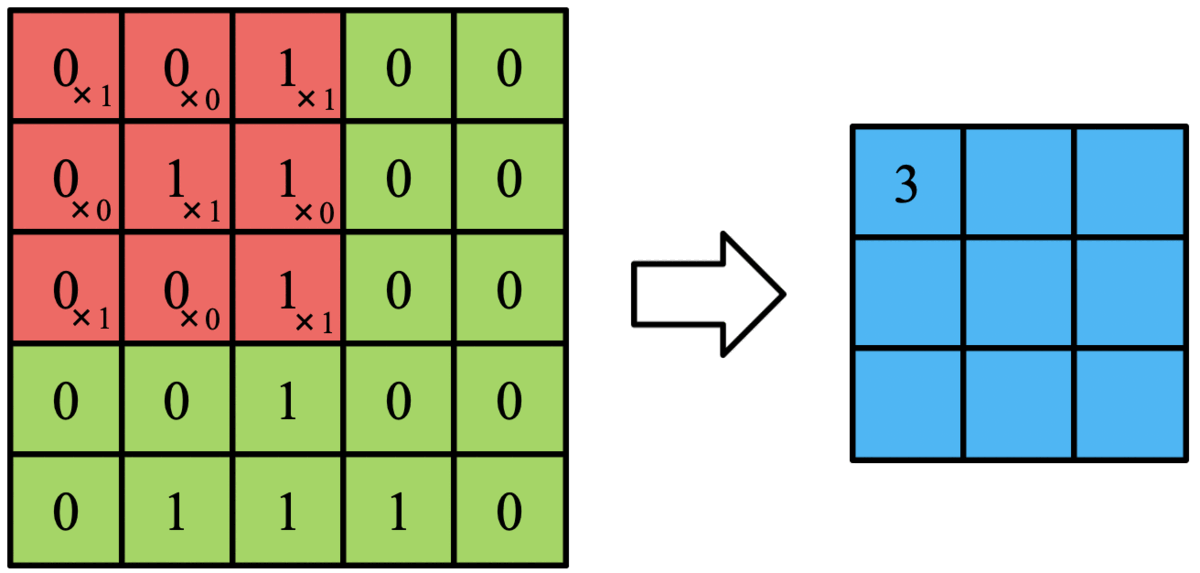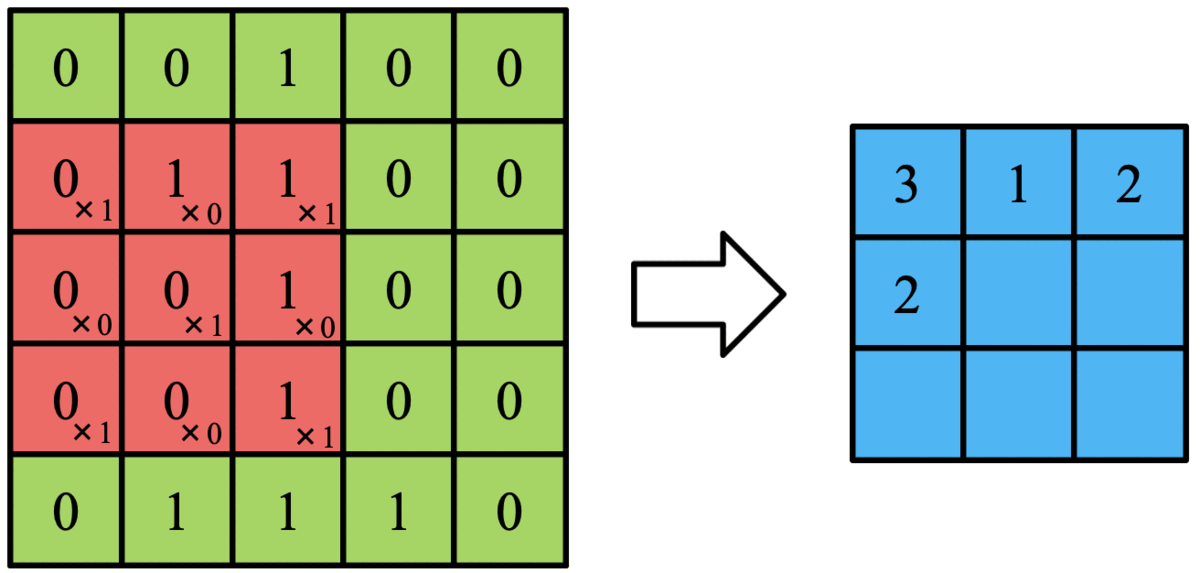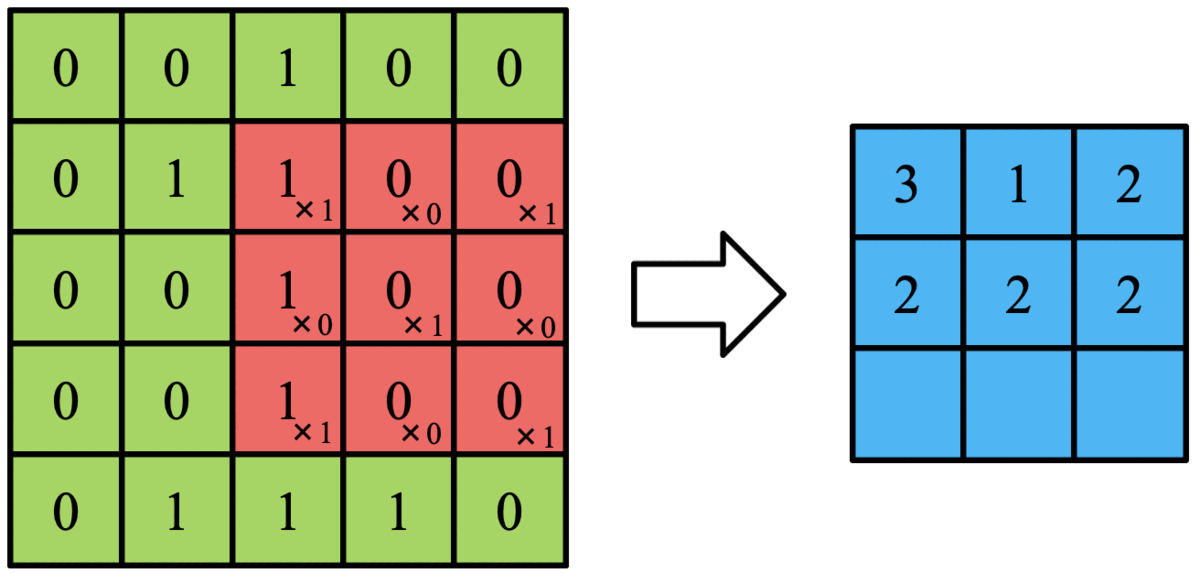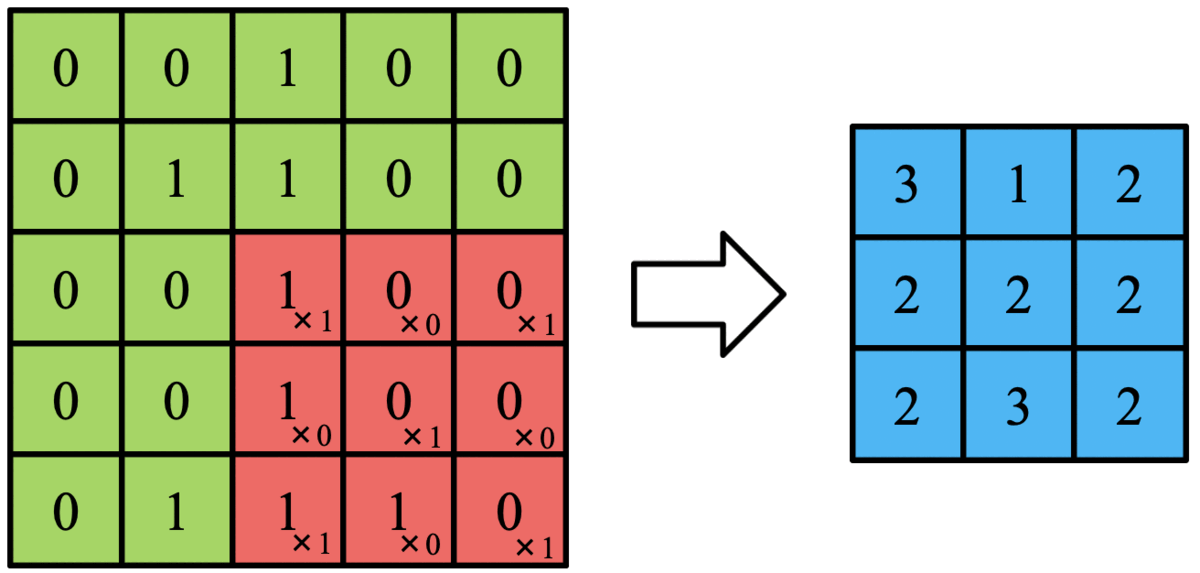
これに対して以下のようにX字に「1」が配置されたフィルタを考えます。
このフィルタと2値画像を重ね合わせ、全ての要素同士を掛け合わせて、最後に足します。
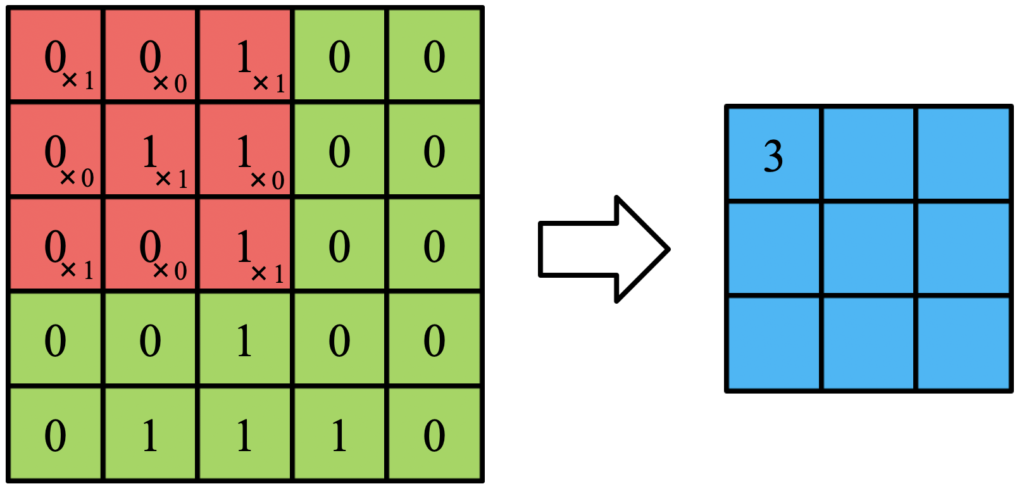
例えば以下のように左上にフィルタを重ねて、左上から右下に向かって計算すると
0x1 + 0x0 + 1×1 + 0x0 + 1×1 + 1×0 + 0x1 + 0x0 + 1×1 = 3
となります。
これを以下のGIFのようにフィルタをスライドさせて画像全体に適応させていきます。
この作業た畳み込みといいます。
Maxpool Layer
次にマックスプーリングについて説明します。
これは先ほどの畳み込みより簡単です!
例えば以下のような画像データがあったとします。
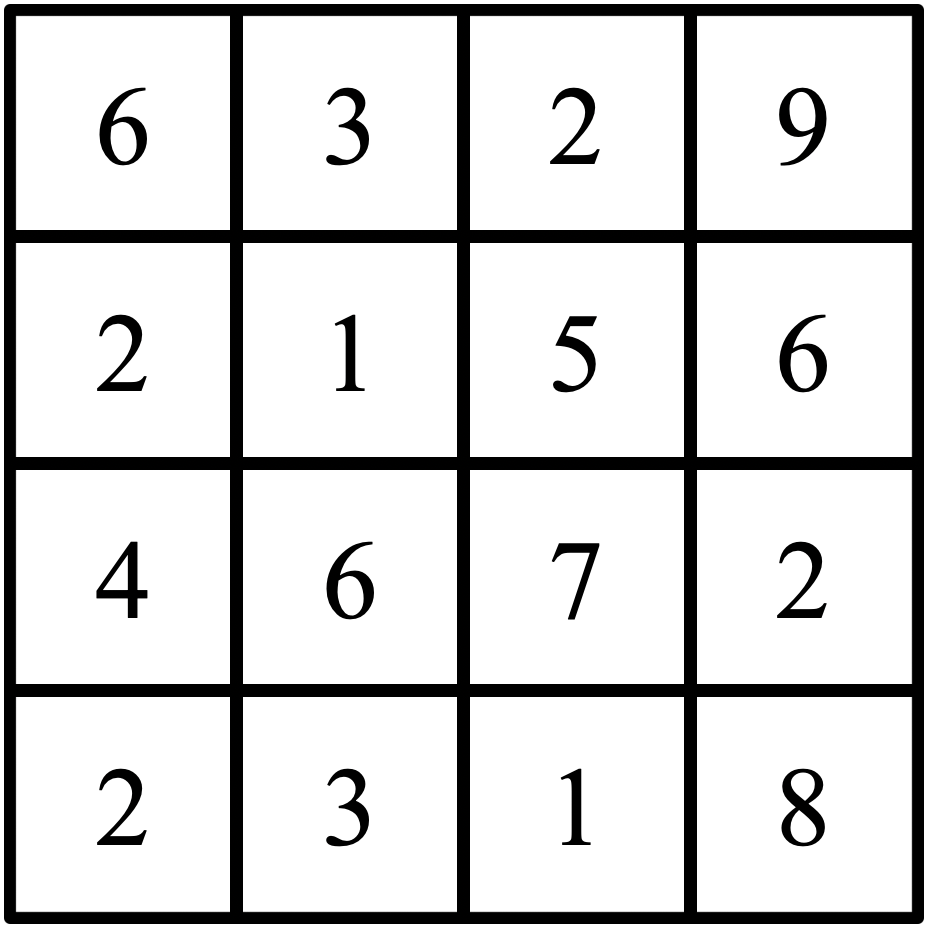
それを以下のように小さな領域に区分けし、最大値をとってきます。
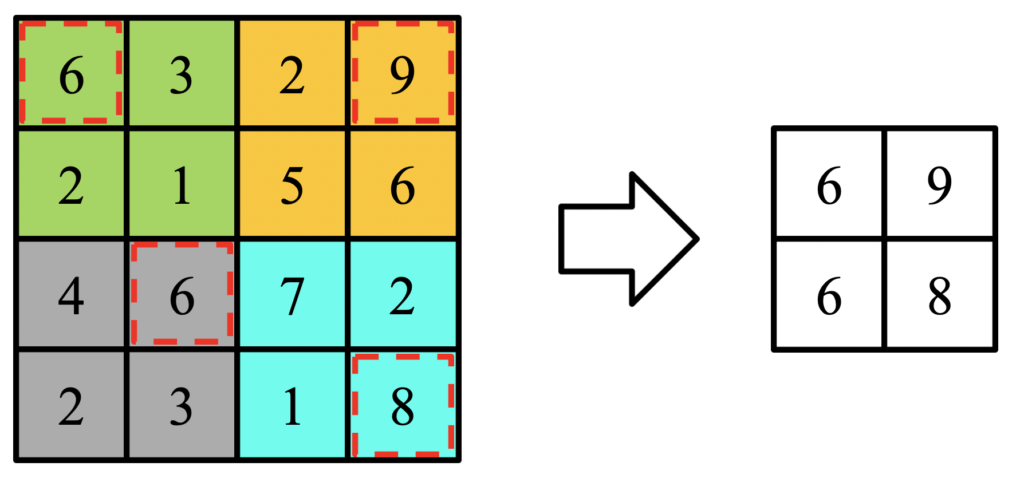
終わりです!
Conn. Layer
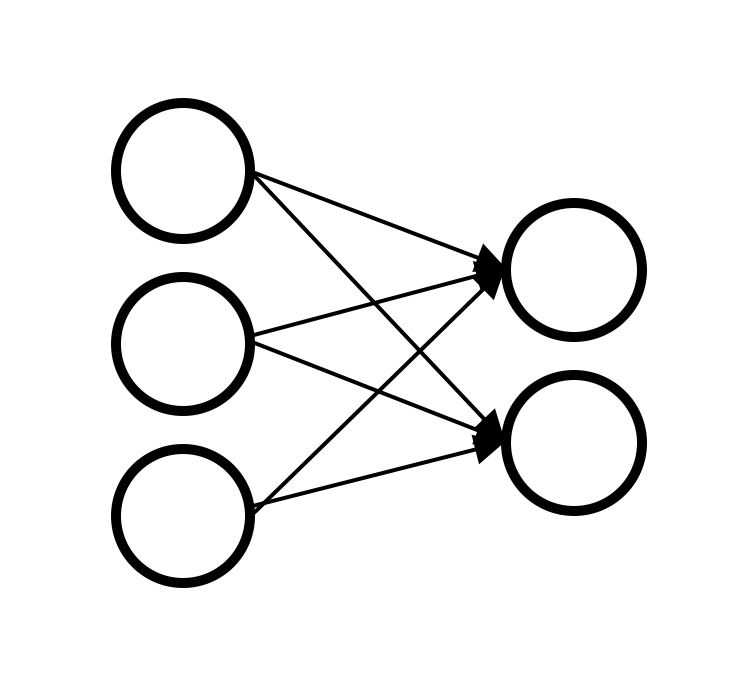
これはつまり、全結合層ですな。
文字通り、全ての要素がつながっているものです。
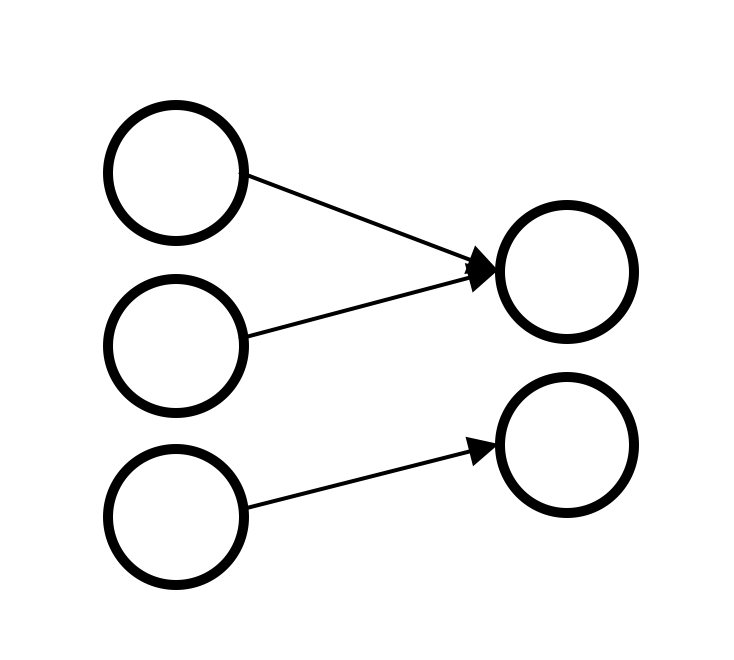
ちなみに以下のように要素が全部繋がっていないものもあるので、わざわざ「全結合層」という名前があります。👇
出力データ
最後に出力データに何が入っているかを見ていきましょう!
(逆に言ったら、CNNの結果どのようなデータが残るのかということです)
これは少し難しいので、気を引き締めてください!
それではまず例を見ていきましょう!以下のように桃太郎一味の写真を撮ったとします。
「bird」、「man」、「monkey」、「dog」を認識できるようにします。(クラス C = 4)

この画像をSxSのグリッドに分けます。(図の場合S=3)👇
その後、そのグリッド内でバウンディングボックスと言われる矩形を作ります。(青色の枠。図中はバウンディングボックスは1つ(B=1))
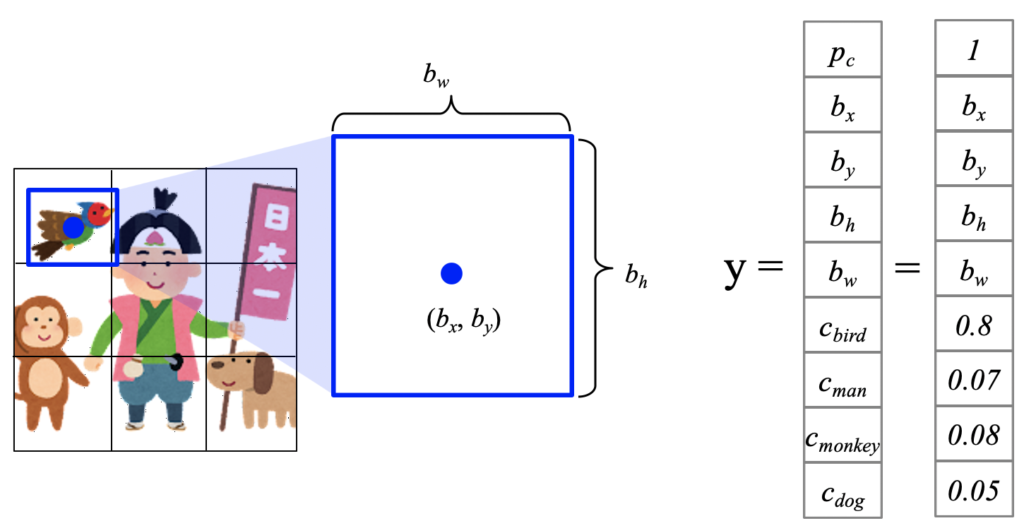
まず、バウンディングボックス内に物体が含まれているかどうかをpcで表します。
pcが1なので、このバウンディングボックスは物体を含んでいることになります。
このバウンディングボックスの情報としては、その中心座標(bx, by)。また、その幅と高さ(bw, bh)が必要になりますね。
次にこのバウンディングボックスで囲まれた物体は何である確率が高いのかを示さないといけません。
上の図中では鳥の可能性が高いと言えますので「y = 」で示しているベクトル内「cbird」に対応する部分は最も高く0.8になっています。
ちなみに、これらの値を全て足すと1になります。
cbird + cman + cmonkey + cdog = 1
一つのグリッドにバウンティングボックスが2つの時(B = 2)の場合を考えてみましょう。
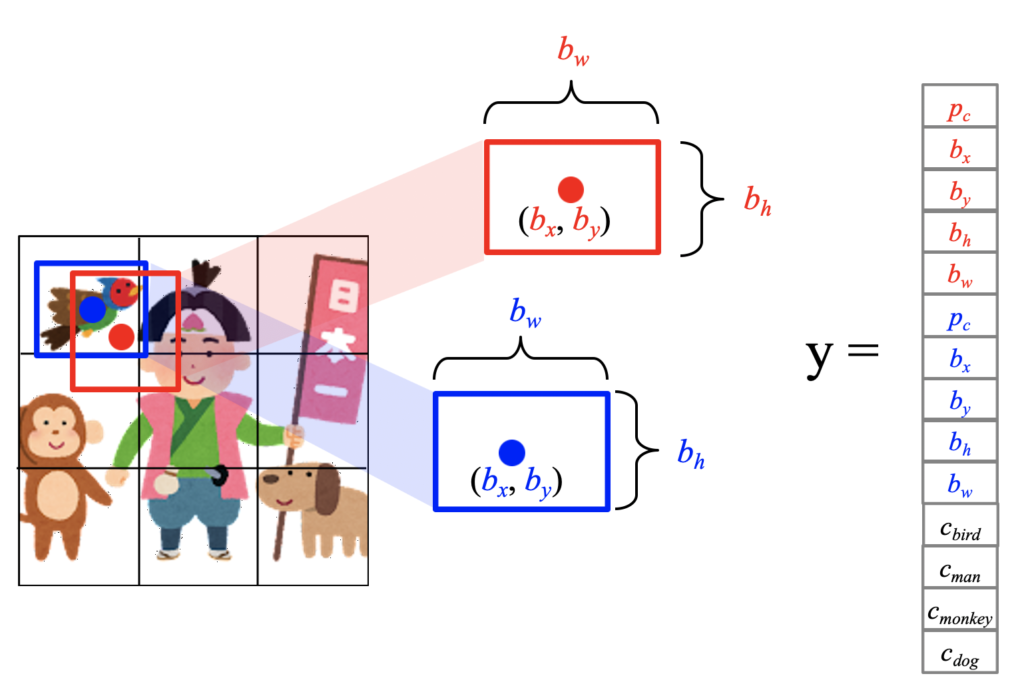
バウンディングボックスが増えることで変わるのは「y = 」で示されるベクトルですね。
示されるバウンディングボックスの分だけyが長くなります。
さぁ、これで大体の説明は終わりました!
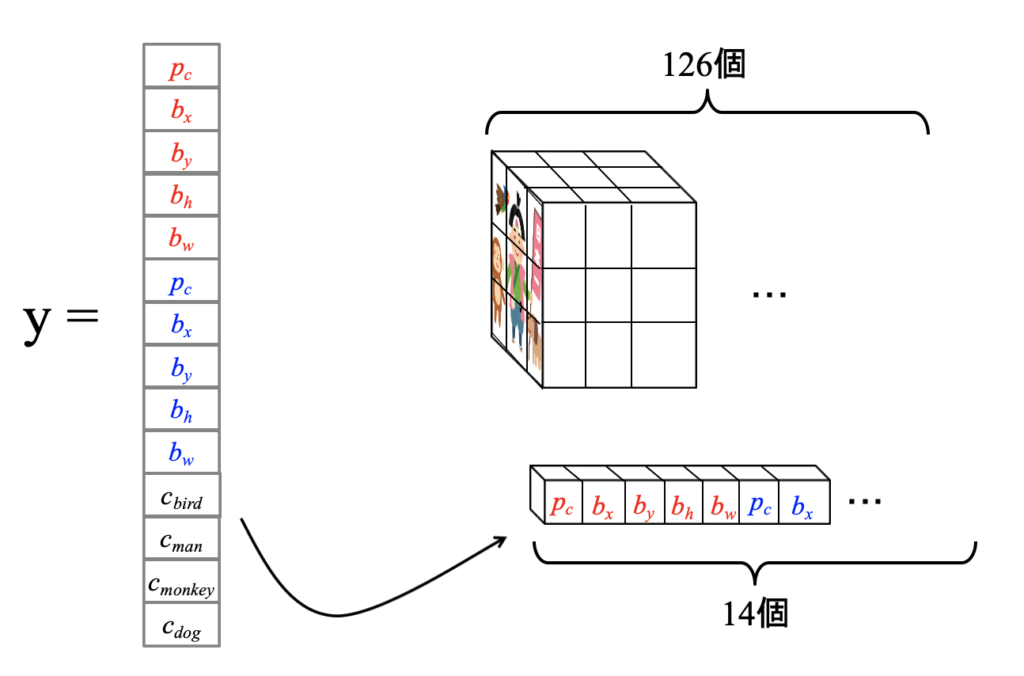
このyは何かというと、一つのグリッドが持っているデータになります。
つまり、上記の例の場合は1グリッドが持っているデータは14個で、
それが9グリッド分あるので、
全体では 14 x 9 = 126 個のデータを持っていることになります!
YOLOの論文では以下の写真で説明してあります。
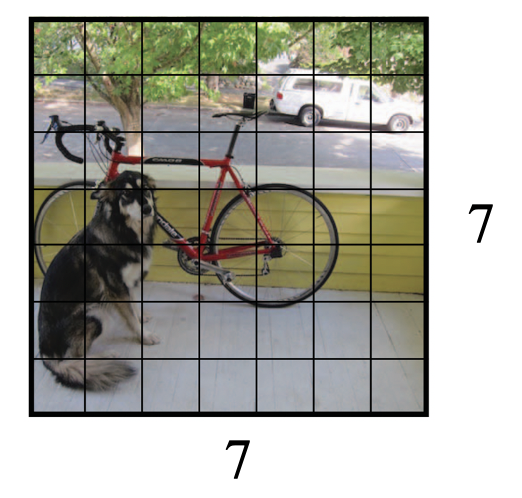
- S = 7 (グリッド数)
- B = 2 (バウンディングボックス数)
- C = 20 (クラスの数)
のとき
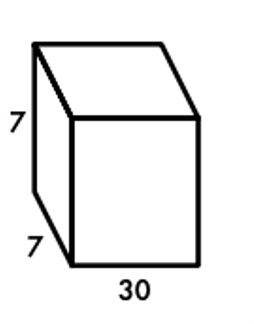
S x S x (B * 5 + C)
= 7 x 7 x (2 * 5 + 20)
= 7 x 7 x 30
となります。
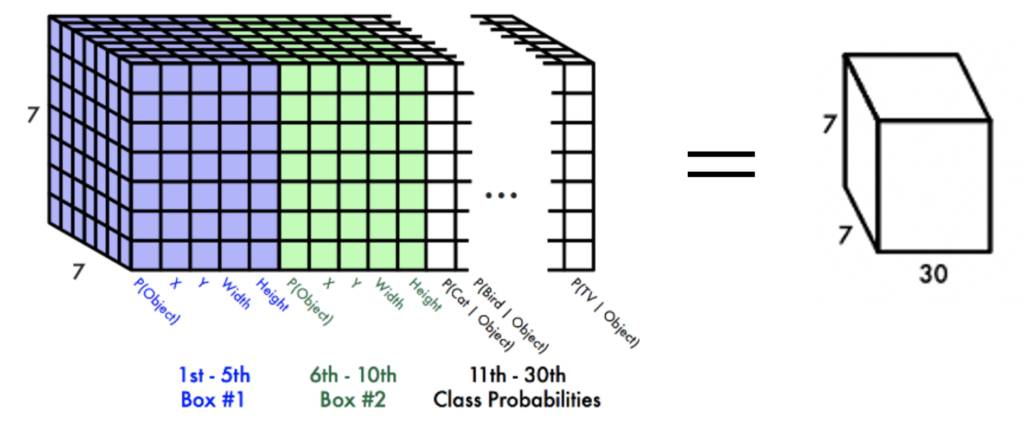
これで出力データの意味が理解できましたね!
次は3のYOLOネットワークに進みましょう!


コメント
見落としてたらすみません。
入力データの説明での、「図中の7」は何を示しているのでしょうか。
ご教授お願い致します。
「1.入力データ」の項目にある”入力説明図”をご覧ください!
緑色の丸で囲まれた 「7」を意味しています!
ちょっとコメントで説明するのは分かりづらいかもしれませんが、
どうぞよろしくお願いします!