
こんにちは、人です。
今回はYOLOの学習モデルを自分で作ってみましょう!
具体的にはこのブロブを読むことで~~.ptファイルを作成することができるようになります!
また、今回はWindowsパソコンで実行します!
1. 写真を撮る
最初は認識させたい物体が写っている写真を撮っていきます。
今回は消しゴムとペンが写っている写真を撮ります。枚数は多ければ多いほどいいと思います。大体10,000枚を目安に写真を撮りましょう。(今回はめんどくさいので50枚です笑)
次にそれらの写真を一つのフォルダにまとめて置いておきます。場所はどこでもいいですが、わかりやすいようにデスクトップにでも置いておきましょう。(フォルダの名前は「erasers_and_pens」にしておきます。)

2. labelimg
次にアノテーションツールであるlebelimgをインストールしていきます。これを使うことで、写真のどこに何が写っているのかを示すテキストファイルを作成することができます。
コマンドプロンプトを開き、以下のように入力します。
pip install labelimg
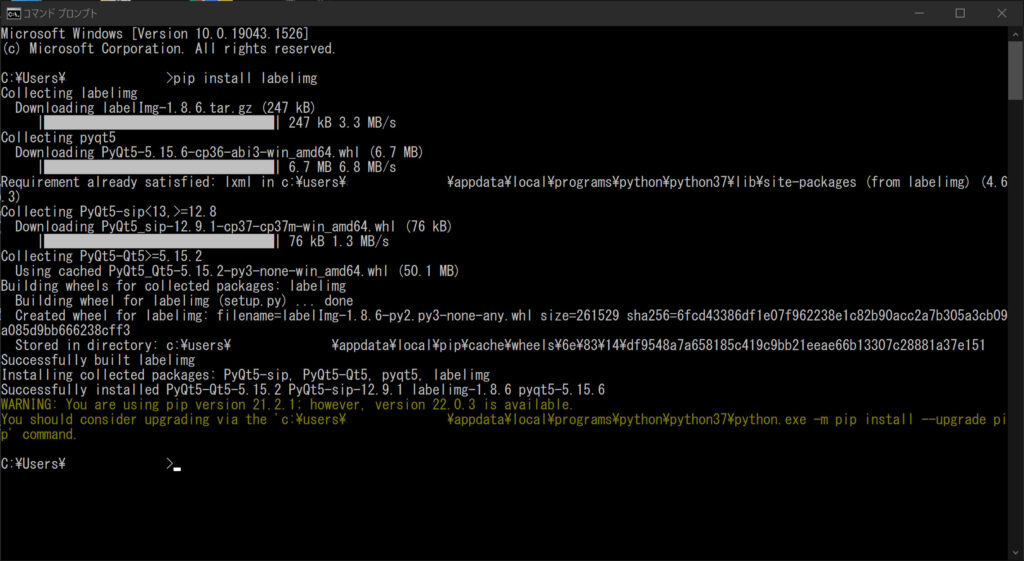
すると、以下のような画面になり、
Successfully installed ~~~~となれば完了です。
次に以下のコマンドを入力してlabelimgを立ち上げます。
labelimg
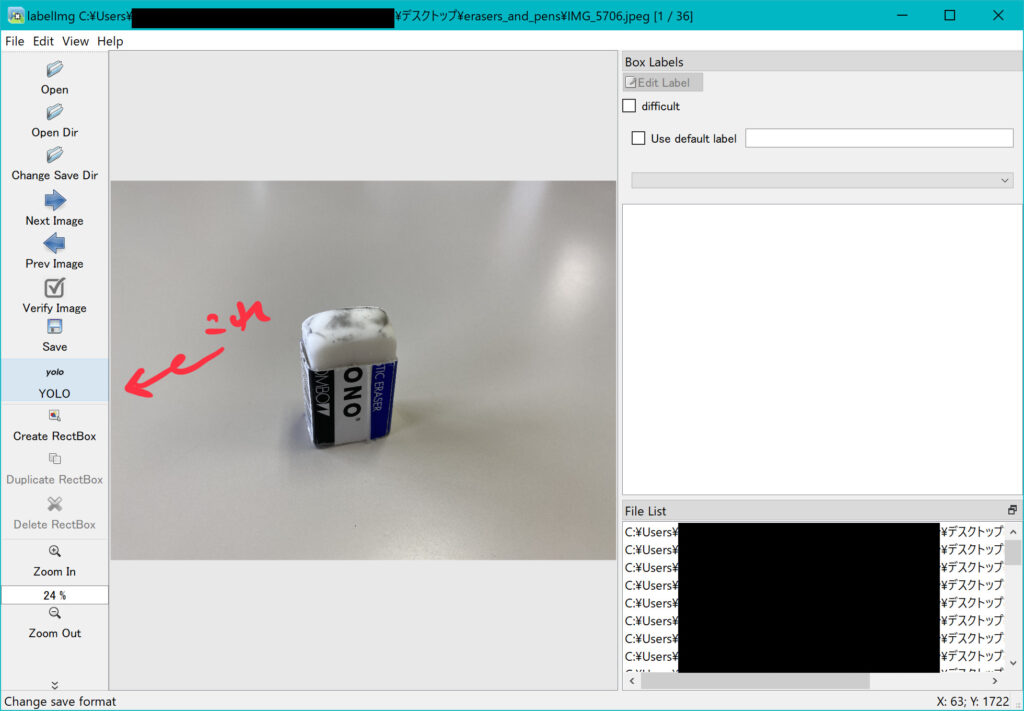
すると、以下のような画面になるかと思います。👇
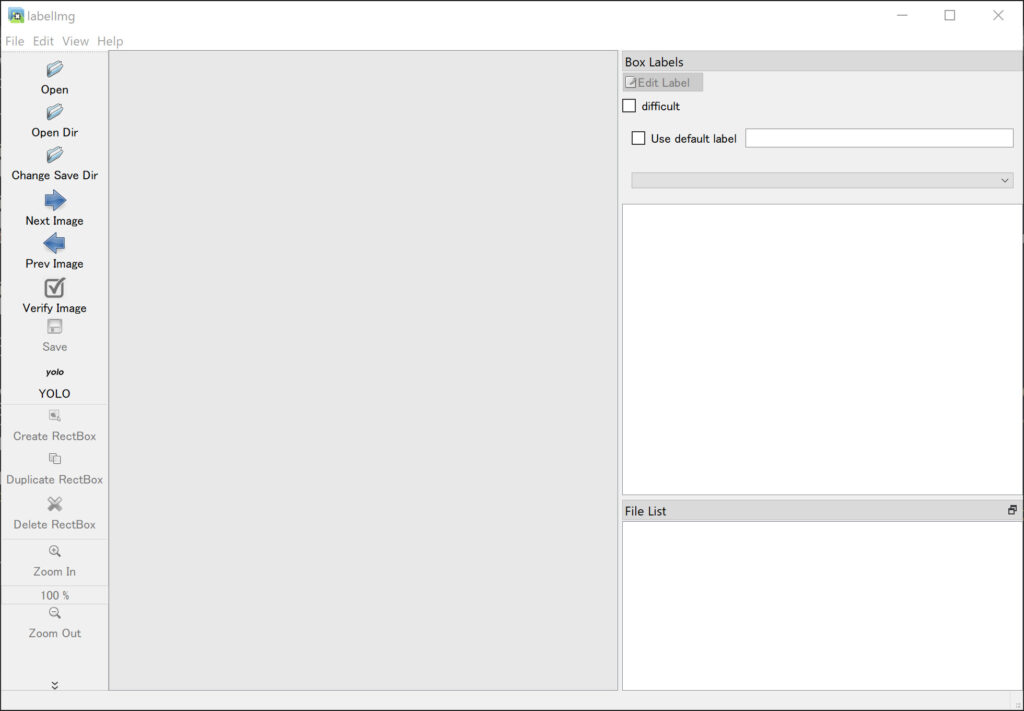
その後、写真をまとめたフォルダを入力フォルダに設定します。👇
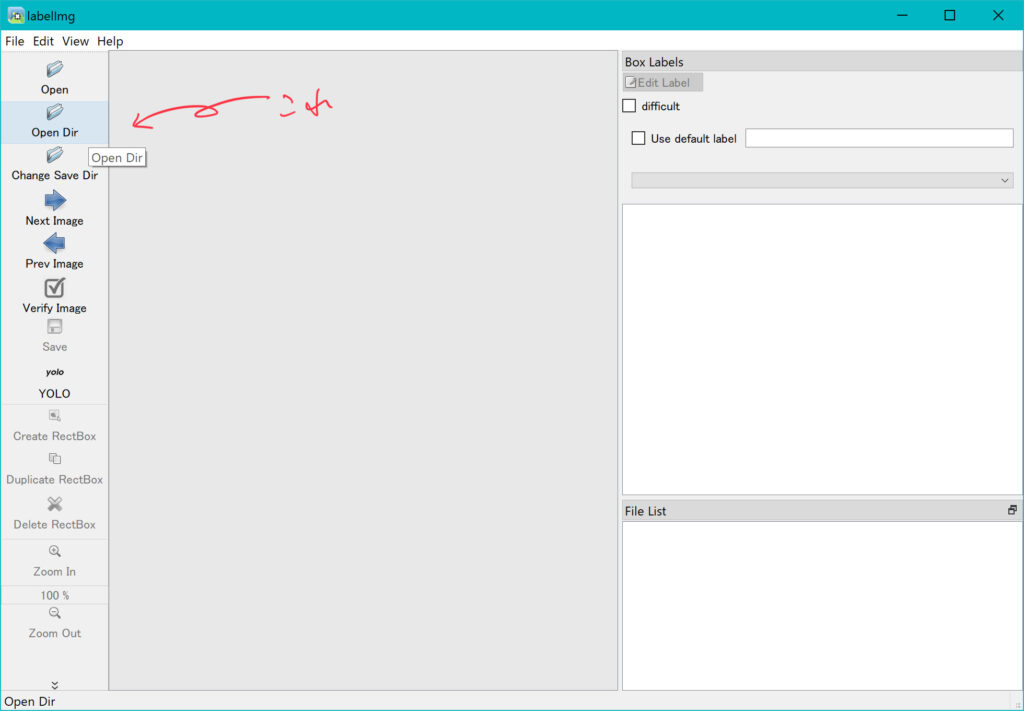
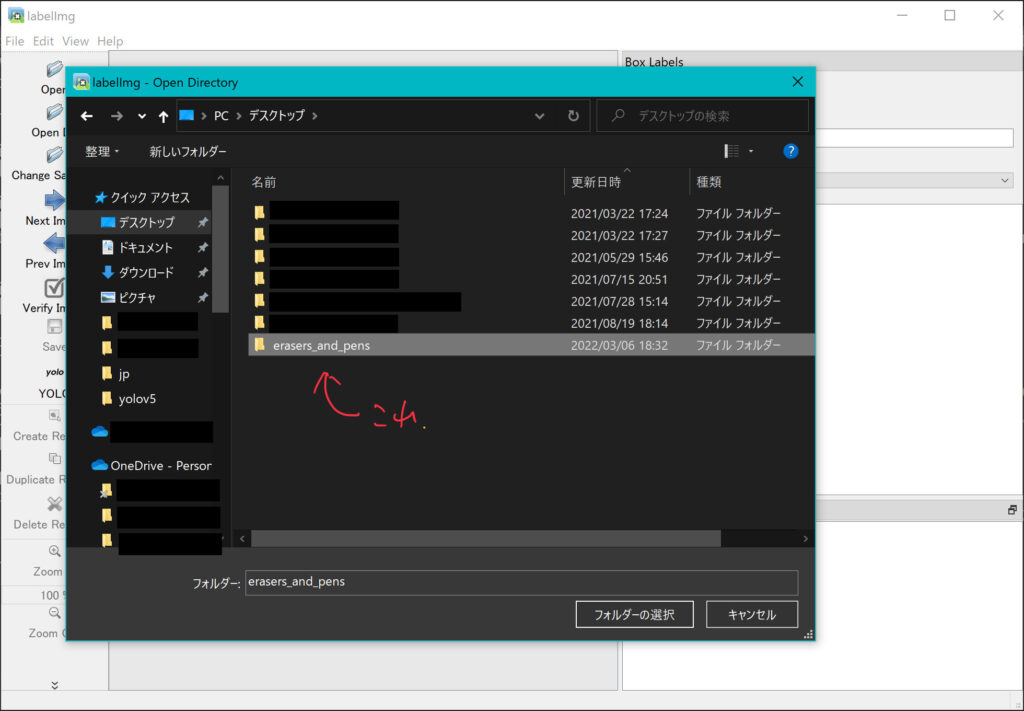
フォルダは適当に名前つけて保存したものを使用します。👇
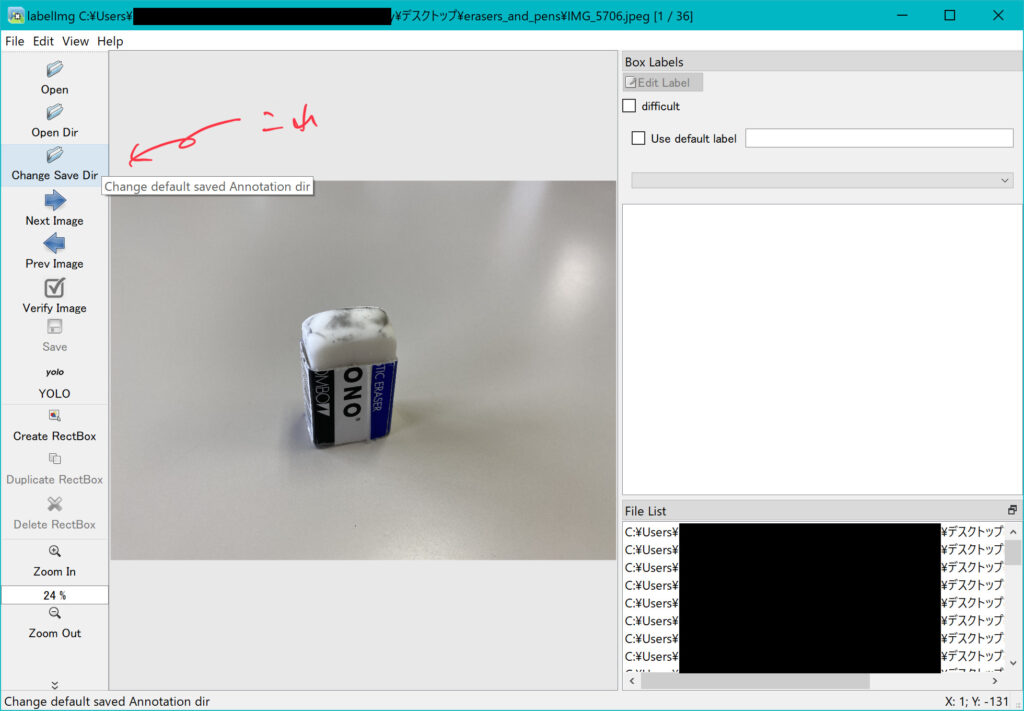
次に保存先のフォルダを設定します。
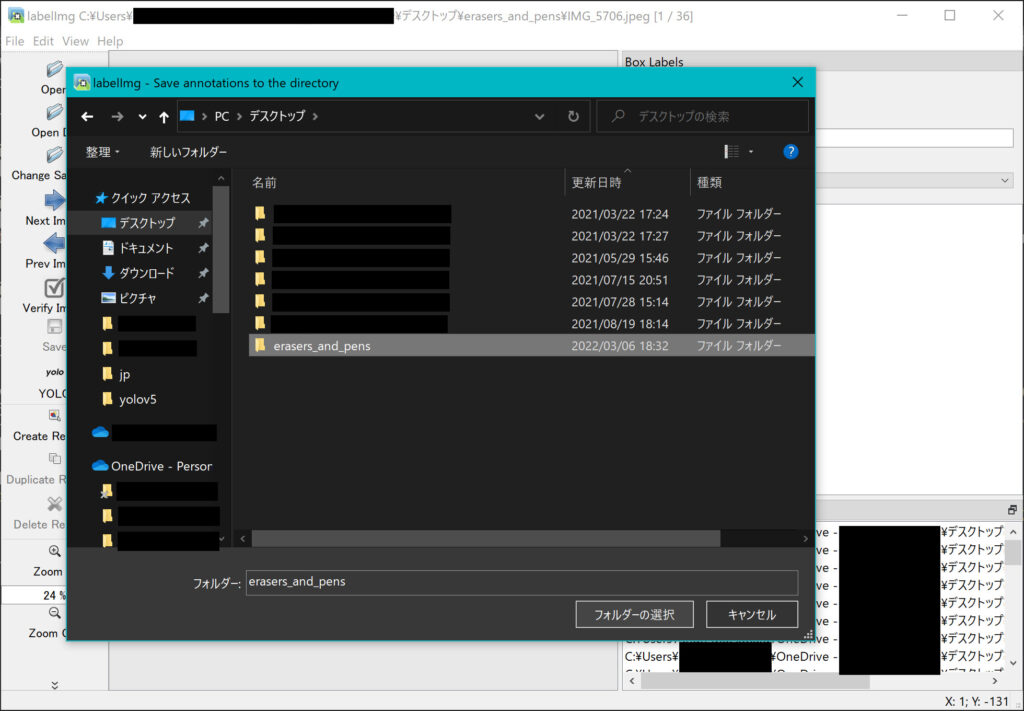
その後、出力形式をYOLOのものに設定します。
下の写真に書いている部分を何度かクリックするとYOLOになると思います。(初期でYOLOになっていてもクリックして設定し直した方がいいと思います。)
次に「labelimg > data > predefined_classes.text」を開きます。👇
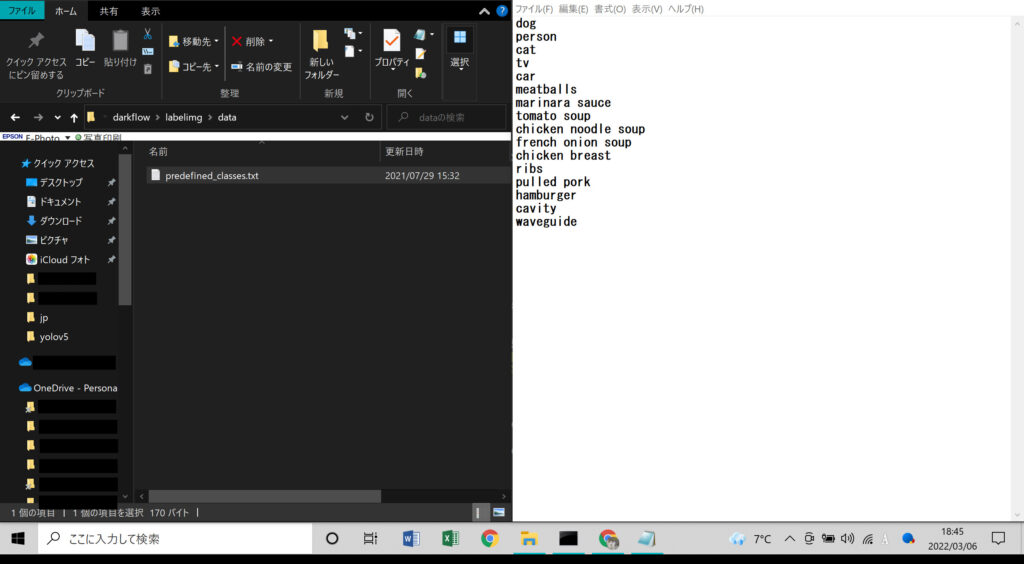
このテキストファイルに書いてある内容を検出したい物体の名前に書き換えておきます。
こんな感じです👇
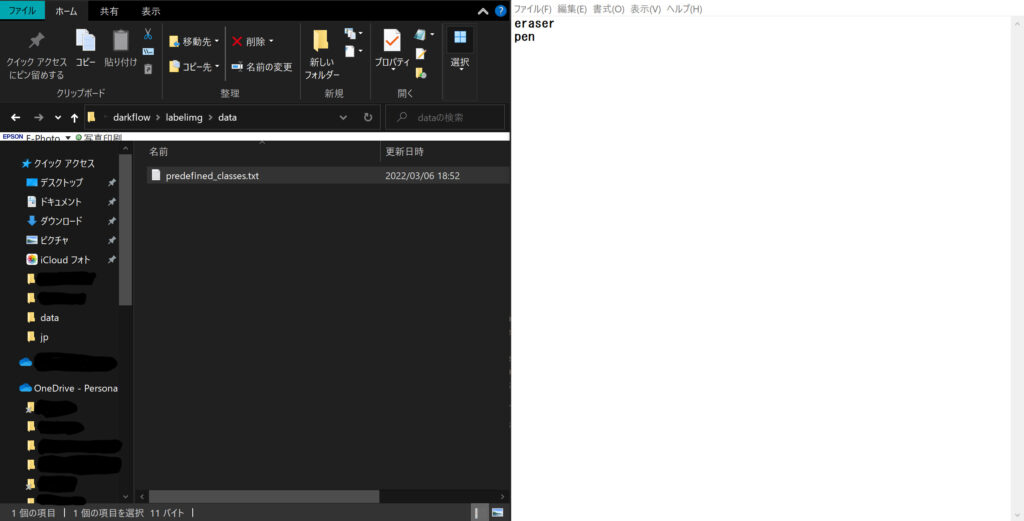
今回の場合だとeraserとpenですね
そしたら、この「predefined_classes.text」を保存してlabelimgの画面に戻ります。
そしてキーボード上で「w」を押します。(もしくは左のメニューバーの中の「Create RectBox」を押してください。
すると、以下のように矩形が出現するので、それで物体を囲んでください。
あとは、新しく現れた出現ボックスで「eraser」を選択して「OK」を押せば大丈夫です。
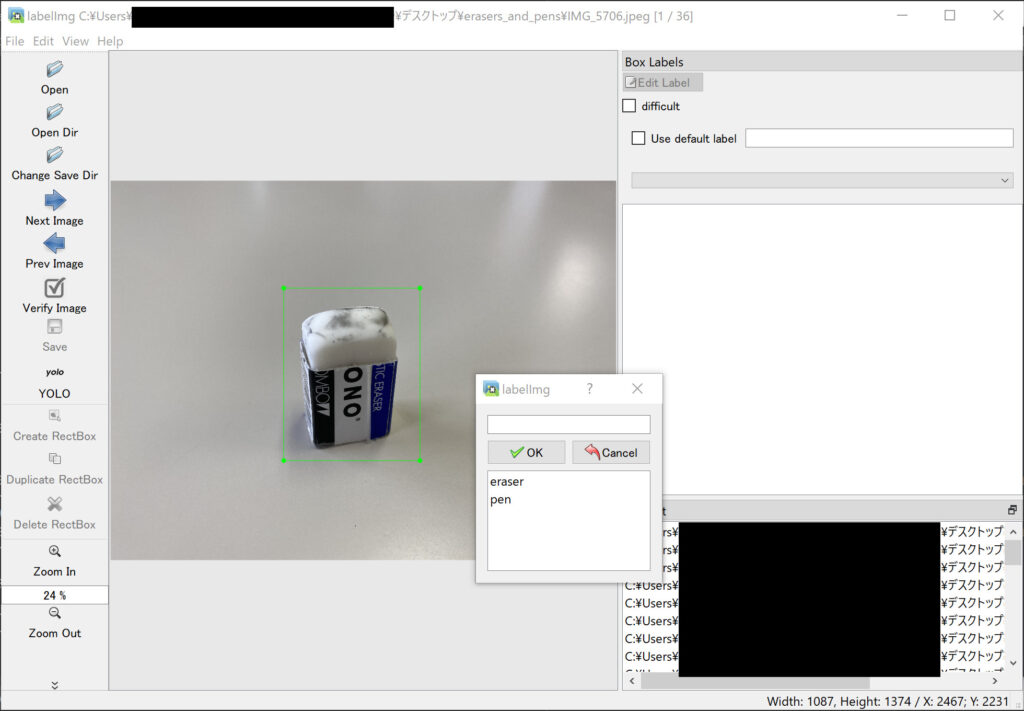
次は、キーボード上で「D」を押して次の画像に進みましょう!
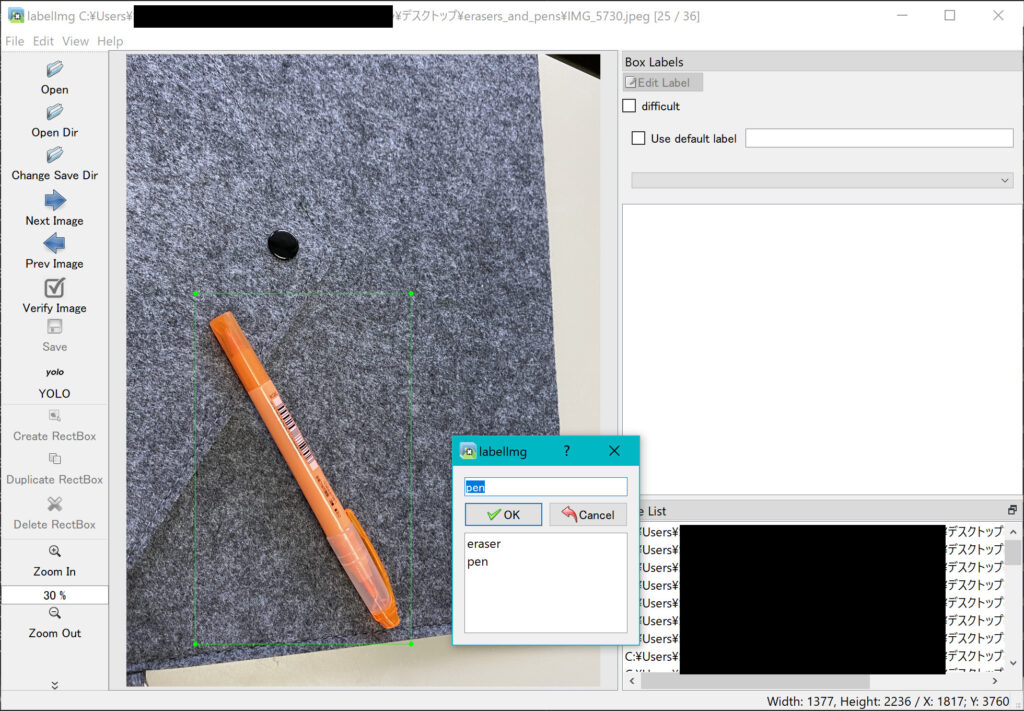
やり方は先ほどと同じですが、今度は出現ボックスで「pen」を選択して「OK」を押します。
もちろん一枚の画像内で複数の物体を選択することもできます。👇
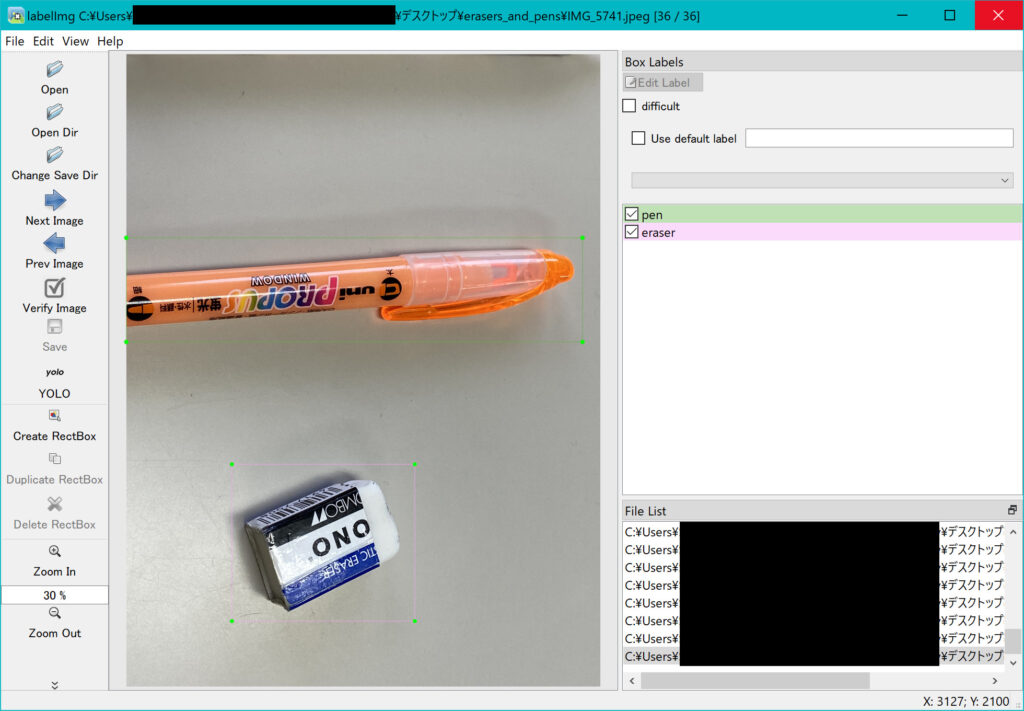
それでは最初に設定した保存先のフォルダの中を見てみましょう。
写真に加えてテキストファイルが新たに作られていることが確認できます。
このテキストファイルには、写真の中にどの物体がどの位置にあるのかが書かれています。
3. Google Drive
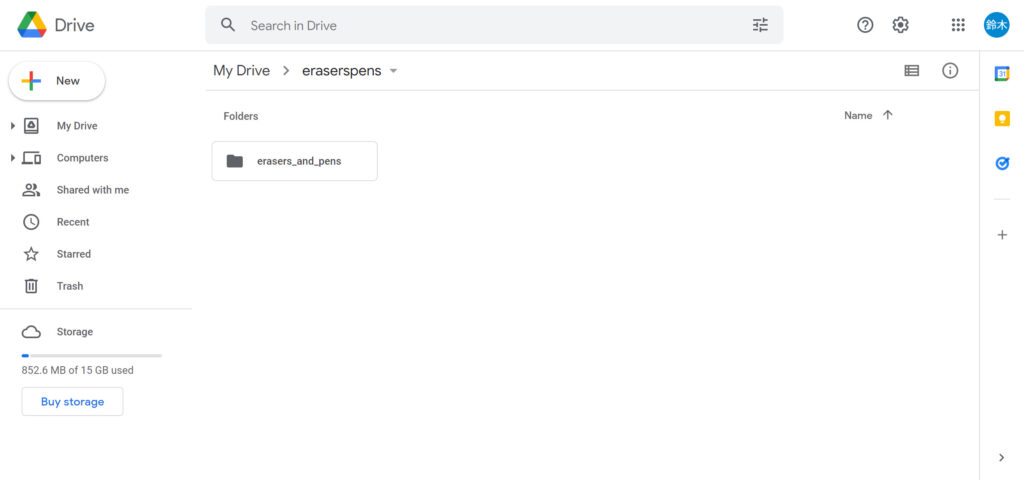
次にGoogle Driveの先ほど保存した出力ファイルを移動させます。
My Driveの中に適当なフォルダ(今回は「eraserspens」)を作ってその中に保存した出力フォルダをアップロードしておきましょう。👇
次にYAMLファイルというものを作ります。
メモ帳を開いて以下のように書き「.yaml」という形式で保存します。
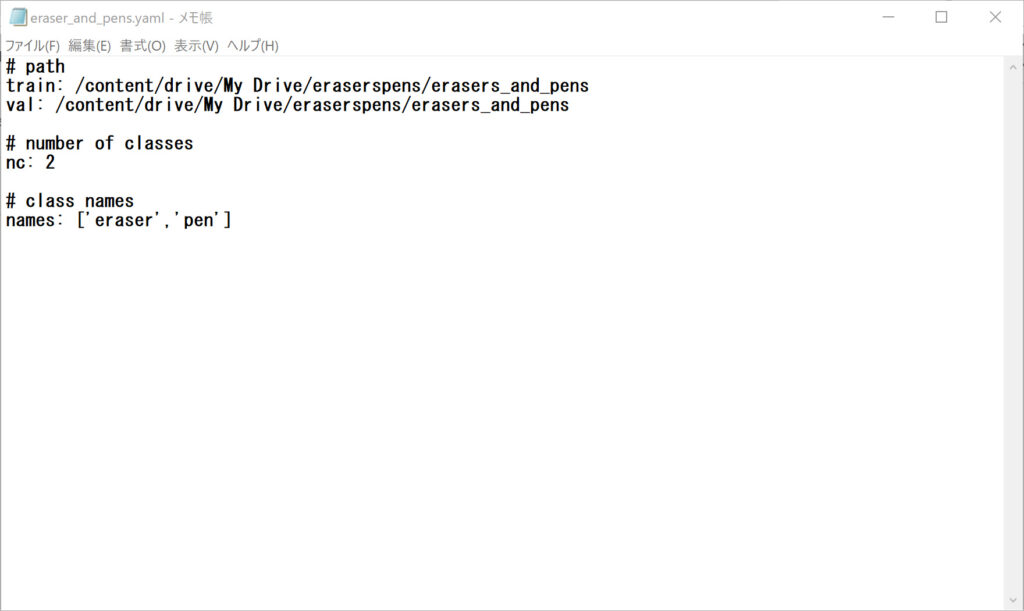
ここで、一応説明を書き加えておきます。
#pathはトレーニングデータと検証用データのパスを指定します。
/content/drive/My Drive/~~~
以降の部分を書き換えれば大丈夫だと思います。
今回はトレーニングデータと検証用データは同じにしますので、どちらも同じパスを指定しています。
もちろん、トレーニングデータと検証用データを別にすることも可能です。
#number of classは検出する物体の種類の数を書いておきます。
今回は消しゴムとペンの2種類ですので、この値は「2」になります。
#class names では検出する物体の名前を書きます。
eraserとpenです。
そしたらこれをとりあえずデスクトップとかに保存しましょう。
次に、My Driveの中に作った適当なファイル(「eraserspens」)の中に入れておきます。👇

4. Google Colab
最後にGoogle Colabで学習を行います。
まずはGoogle Colabを開いて新しいノートブックを作りましょう。👇
次に、わかりやすいようにノートブックの名前を変えておきます。👇
また、Google ColabでGPUが使えるようにします。
最初に「ランタイムのタイプを変更」を選択します。👇
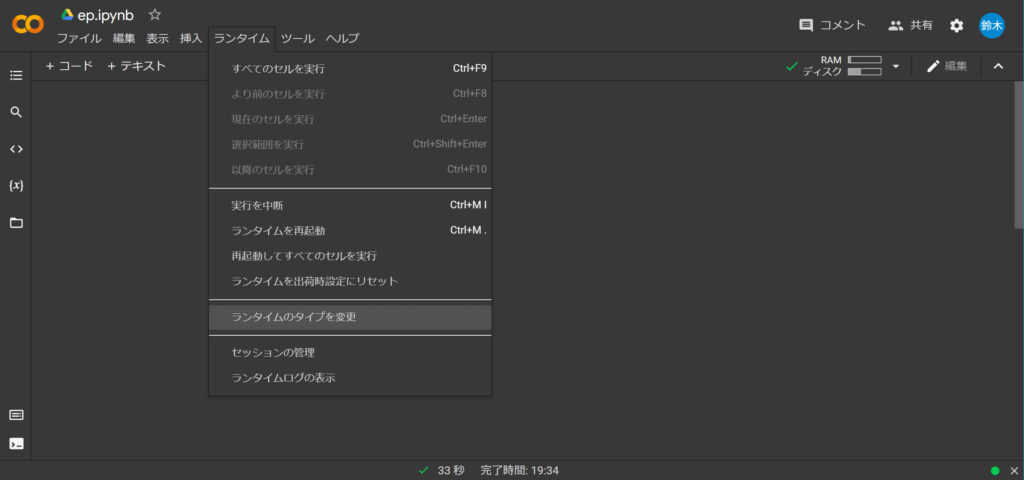
その後、ランタイムのタイプで「GPU」を設定します。
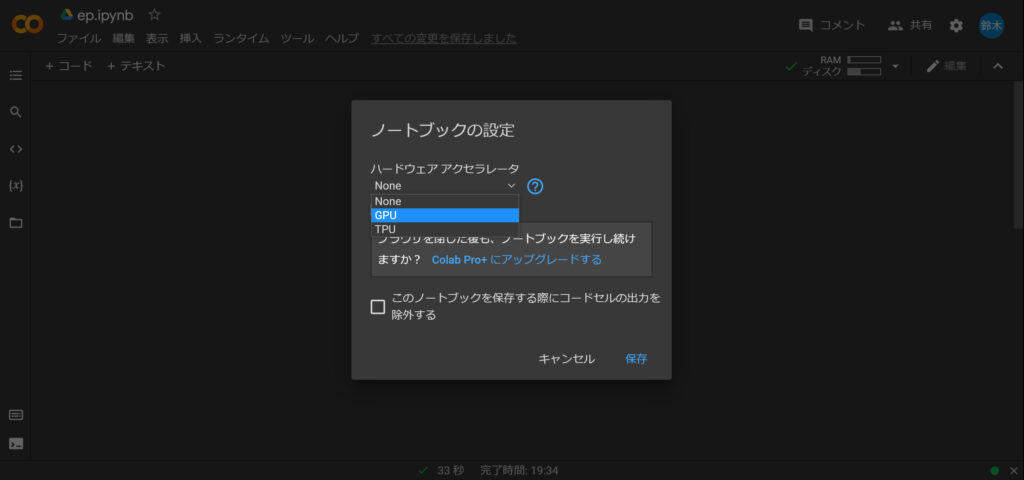
最後に「保存」を押して終了です。
最後に学習を行っていきます。
結論から言えば下記に示すプログラムを順番に実行していけば大丈夫です。👇
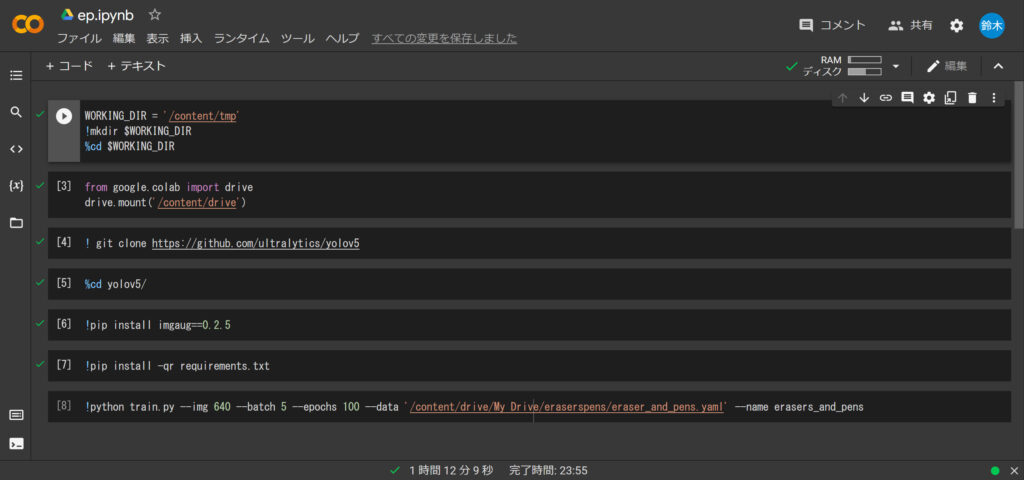
まずは一行目からいきましょう。
WORKING_DIR = '/content/tmp'
!mkdir $WORKING_DIR
%cd $WORKING_DIR実行すると下記のような画面にまります。
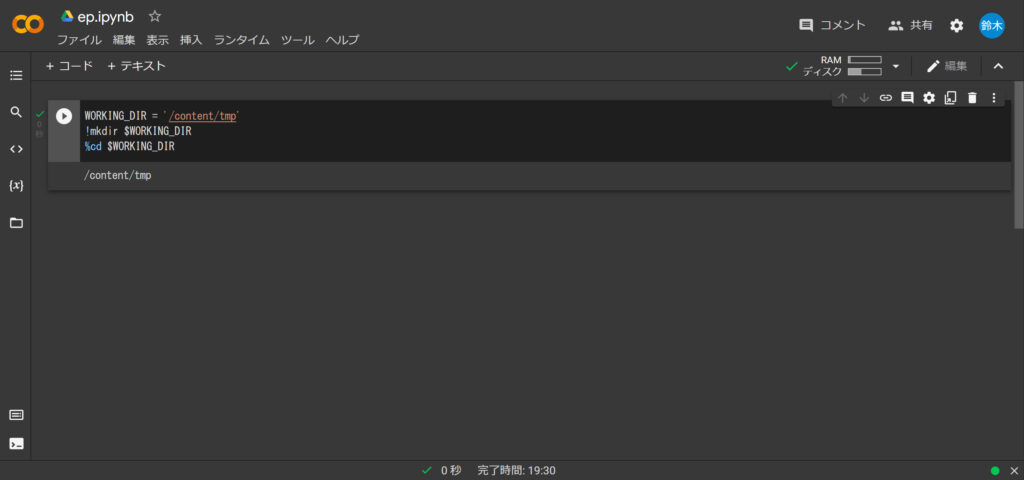
次に2行目を実行してみましょう。
from google.colab import drive
drive.mount('/content/drive')すると、下記の写真のように「このノートブックにGoogleドライブのファイルへのアクセスを許可しますか?」というポップアップが出るので、接続してしまいましょう。
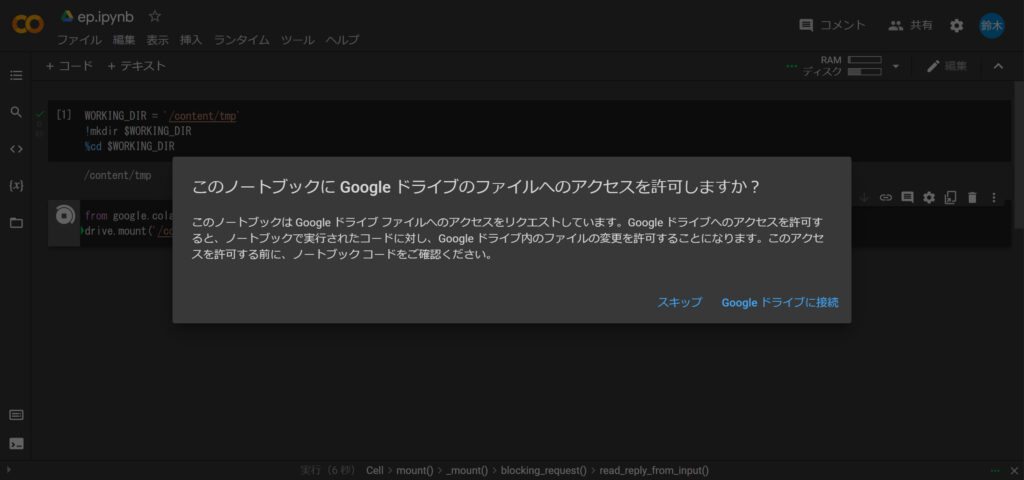
次は、Google Colab内にYOLOをインストールします。
! git clone https://github.com/ultralytics/yolov5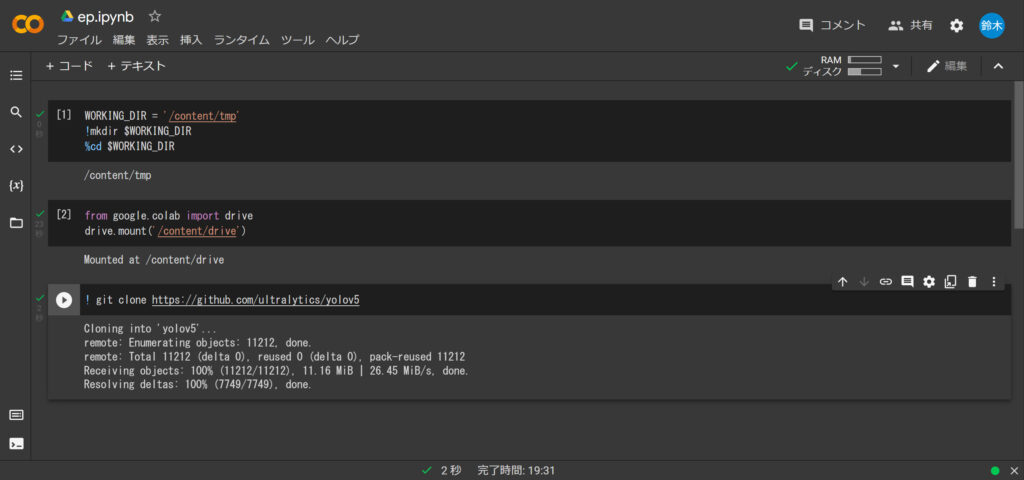
その後、YOLOフォルダに移動します。
%cd yolov5/
また、imgaugをインストールします。
!pip install imgaug==0.2.5
次はrequirements.txtで必要なものをインストールしてきます。
!pip install -qr requirements.txt
さぁ、最後です。
!python train.py --img 640 --batch 5 --epochs 100 --data '/content/drive/My Drive/eraserspens/erasers_and_pens.yaml' --name erasers_and_pensすると、学習が開始されます。
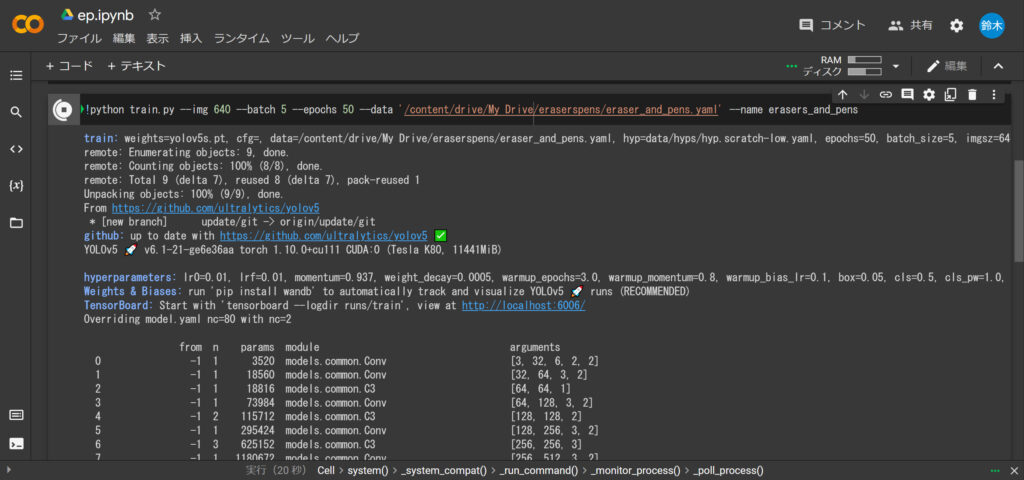
学習には結構な時間がかかります。場合によって10時間とかは平気でかかるので覚悟しておいてください!
こちらが学習が終わった結果になります。👇
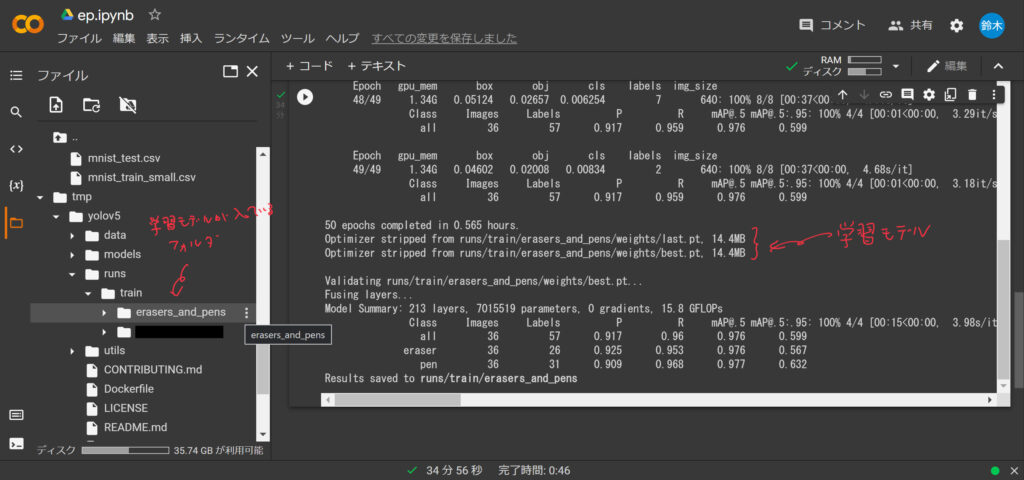
写真にも書いていますが、学習が終わると「学習モデル」が生成されますので、それを取り出す必要があります。
「学習モデル」が生成されたフォルダは最後の出力結果に書いてあります。👆
「学習モデル」にはbest.ptとlast.ptの2種類があります。
best.ptは学習で最も良い結果を反映させたもので、last.ptは学習の最後の結果を反映させたものです。
このフォルダを開いて実際にあるか確認してみます。
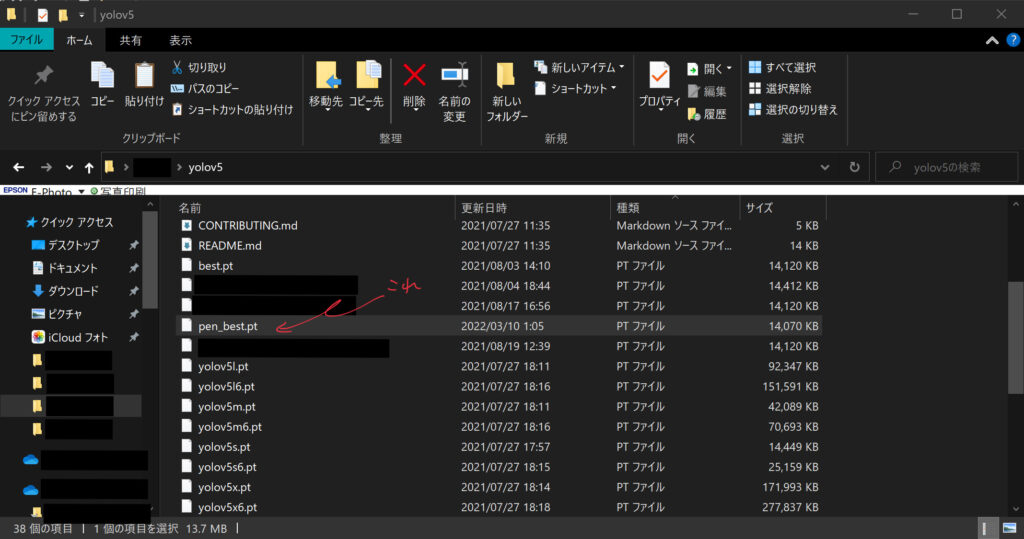
今回はbest.ptを使います。
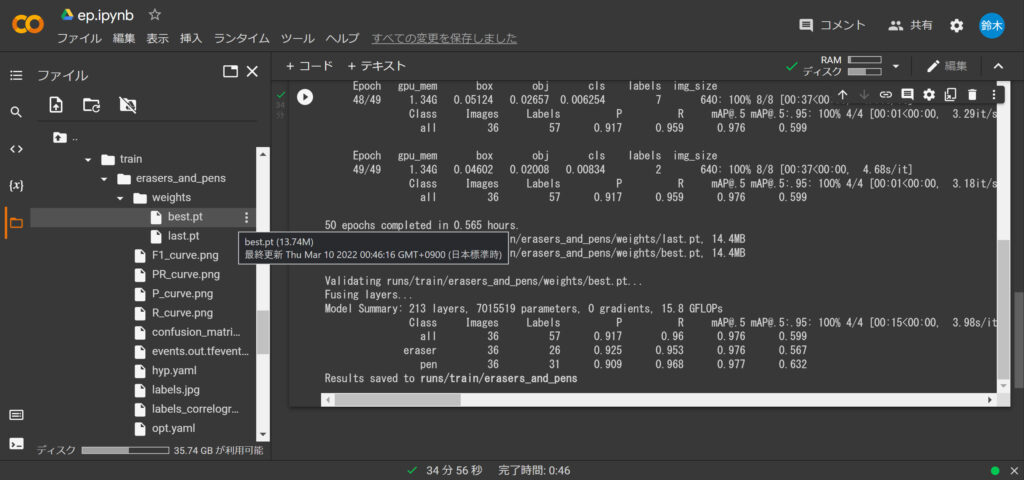
best.ptをダウンロードして適当に名前をつけて保存しましょう。
お疲れ様でした!
これで学習モデルを作成することができました!
あとは、こちらのサイトより自分が作成した学習モデルを用いて物体検出をやってみてください!



コメント