
こんにちは、人です。
今日はYOLOを用いて物体検出を行なった上でOpenCVを用いた直線検出を行いたいと思います。
対象読者
- YOLOを使っている人(または使ってみたい人)
- OpenCVと組み合わせたい人
この記事を書いた理由
最近YOLOの勉強をしてたんですけど、YOLOの応用がなかなかサイトに載ってなかったので書いてみました。
環境構築
*)一連の環境構築については別記事でまとめましたので、こちらも読んでみてください!
YOLOはGoogle Colab内でもできるみたいですが今回はカメラを用いるため、環境はローカルPCの中に構築します。
yolov5とPyTorch、OpenCVがあれば大丈夫だと思います。
訓練済みデータも必要ですねこちらからダウンロードしてください。データはyolov5ファイルの中に入れてください。
ファイルとしてはこんな感じです。
環境構築のために参考にしたサイトを以下に示します。
- yolov5のインストールはこちら。
- gitの使い方サイトはこちら。
- gitのインストールサイトはこちら。
- CUDAのインストールサイトはこちら。11.1.1 versionがいいっぽい。
- PyTorchのインストールサイトはこちら。
最後に自分のモジュールを一覧で示します。
Package Version
----------------------- ---------------------
absl-py 0.13.0
astor 0.8.1
astunparse 1.6.3
biwrap 0.1.6
cached-property 1.5.2
cachetools 4.2.2
certifi 2021.5.30
charset-normalizer 2.0.3
colorama 0.4.4
cycler 0.10.0
Cython 0.29.24
flatbuffers 1.12
gast 0.2.2
google-auth 1.34.0
google-auth-oauthlib 0.4.4
google-pasta 0.2.0
grpcio 1.34.1
h5py 3.1.0
idna 3.2
importlib-metadata 4.6.1
Keras 2.3.1
Keras-Applications 1.0.8
keras-nightly 2.5.0.dev2021032900
Keras-Preprocessing 1.1.2
kiwisolver 1.3.1
lxml 4.6.3
Markdown 3.3.4
matplotlib 3.4.2
mock 4.0.3
numpy 1.19.5
oauthlib 3.1.1
opencv-python 4.5.3.56
opencv-python-headless 4.5.3.56
opt-einsum 3.3.0
pandas 1.3.1
Pillow 8.3.1
pip 21.2.1
protobuf 3.17.3
pyasn1 0.4.8
pyasn1-modules 0.2.8
pycocotools 2.0.2
pyparsing 2.4.7
PyQt5 5.15.4
PyQt5-Qt5 5.15.2
PyQt5-sip 12.9.0
python-dateutil 2.8.2
pytz 2021.1
PyYAML 5.4.1
requests 2.26.0
requests-oauthlib 1.3.0
rsa 4.7.2
scipy 1.7.0
seaborn 0.11.1
setuptools 47.1.0
six 1.15.0
tensorboard 1.14.0
tensorboard-data-server 0.6.1
tensorboard-plugin-wit 1.8.0
tensorflow 1.14.0
tensorflow-estimator 1.14.0
tensorflow-gpu 2.5.0
tensorflow-plot 0.3.2
termcolor 1.1.0
thop 0.0.31.post2005241907
torch 1.9.0
torchvision 0.10.0
tqdm 4.61.2
typing-extensions 3.7.4.3
urllib3 1.26.6
utils 1.0.1
Werkzeug 2.0.1
wheel 0.36.2
wrapt 1.12.1
zipp 3.5.0実行
それでは実行していきましょう。
yolov5ファイルには元々detect.pyがあります。これを改造してOpenCVと組み合わせます。
とりあえずdetect0.pyをyolov5フォルダの中に作りましょう。(以下中身です。)
import argparse
import sys
import time
from pathlib import Path
from scipy.spatial import distance as dist
import numpy as np
import cv2
import torch
import torch.backends.cudnn as cudnn
from PIL import Image, ImageOps
FILE = Path(__file__).absolute()
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
from models.experimental import attempt_load
from utils.datasets import LoadStreams, LoadImages
from utils.general import check_img_size, check_requirements, check_imshow, colorstr, non_max_suppression, \
apply_classifier, scale_coords, xyxy2xywh, strip_optimizer, set_logging, increment_path, save_one_box
from utils.plots import colors, plot_one_box
from utils.torch_utils import select_device, load_classifier, time_sync
@torch.no_grad()
def run(weights='yolov5s.pt', # model.pt path(s)
source='data/images', # file/dir/URL/glob, 0 for webcam
imgsz=640, # inference size (pixels)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project='runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
):
save_img = not nosave and not source.endswith('.txt') # save inference images
webcam = source.isnumeric() or source.endswith('.txt') or source.lower().startswith(
('rtsp://', 'rtmp://', 'http://', 'https://'))
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Initialize
set_logging()
device = select_device(device)
half &= device.type != 'cpu' # half precision only supported on CUDA
# Load model
w = weights[0] if isinstance(weights, list) else weights
classify, pt, onnx = False, w.endswith('.pt'), w.endswith('.onnx') # inference type
stride, names = 64, [f'class{i}' for i in range(1000)] # assign defaults
if pt:
model = attempt_load(weights, map_location=device) # load FP32 model
stride = int(model.stride.max()) # model stride
names = model.module.names if hasattr(model, 'module') else model.names # get class names
if half:
model.half() # to FP16
if classify: # second-stage classifier
modelc = load_classifier(name='resnet50', n=2) # initialize
modelc.load_state_dict(torch.load('resnet50.pt', map_location=device)['model']).to(device).eval()
elif onnx:
check_requirements(('onnx', 'onnxruntime'))
import onnxruntime
session = onnxruntime.InferenceSession(w, None)
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
if webcam:
view_img = check_imshow()
cudnn.benchmark = True # set True to speed up constant image size inference
dataset = LoadStreams(source, img_size=imgsz, stride=stride)
bs = len(dataset) # batch_size
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride)
bs = 1 # batch_size
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
if pt and device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # run once
t0 = time.time()
for path, img, im0s, vid_cap in dataset:
if pt:
img = torch.from_numpy(img).to(device)
img = img.half() if half else img.float() # uint8 to fp16/32
elif onnx:
img = img.astype('float32')
img /= 255.0 # 0 - 255 to 0.0 - 1.0
if len(img.shape) == 3:
img = img[None] # expand for batch dim
# Inference
t1 = time_sync()
if pt:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(img, augment=augment, visualize=visualize)[0]
elif onnx:
pred = torch.tensor(session.run([session.get_outputs()[0].name], {session.get_inputs()[0].name: img}))
# NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
t2 = time_sync()
# Second-stage classifier (optional)
if classify:
pred = apply_classifier(pred, modelc, img, im0s)
# Process predictions
for i, det in enumerate(pred): # detections per image
if webcam: # batch_size >= 1
p, s, im0, frame = path[i], f'{i}: ', im0s[i].copy(), dataset.count
else:
p, s, im0, frame = path, '', im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # img.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # img.txt
s += '%gx%g ' % img.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
print(det) #output[topleft(x), topleft(y), bottomright(x), bottomright(y), confidence score, class number]
detx1 = int(det[0][0].numpy())
dety1 = int(det[0][1].numpy())
detx2 = int(det[0][2].numpy())
dety2 = int(det[0][3].numpy())
print(detx1)
print(dety1)
print(detx2)
print(dety2)
im0 = np.array(im0)
im1 = im0[dety1:dety2, detx1:detx2]
gray = cv2.cvtColor(im1, cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray, 60, 80)
edges = cv2.dilate(edges, None, iterations=1)
edges = cv2.erode(edges, None, iterations=1)
cv2.imshow("im1", im1)
################################
# 直線検出
################################
lines = cv2.HoughLinesP(edges, 1, np.pi/180, 100, minLineLength=100, maxLineGap=3000)
if lines is None:
print("###### no lines #####")
else:
lines = lines.tolist()
for x1,y1,x2,y2 in lines[0]:
cv2.line(im0,(x1+detx1,y1+dety1),(x2+detx1,y2+dety1),(0,0,255),4)
# Print results
for c in det[:, -1].unique():
n = (det[:, -1] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
if save_txt: # Write to file
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
with open(txt_path + '.txt', 'a') as f:
f.write(('%g ' * len(line)).rstrip() % line + '\n')
if save_img or save_crop or view_img: # Add bbox to image
c = int(cls) # integer class
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_thickness=line_thickness)
if save_crop:
save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
# Print time (inference + NMS)
print(f'{s}Done. ({t2 - t1:.3f}s)')
# Stream results
if view_img:
cv2.imshow(str(p), im0)
cv2.waitKey(1) # 1 millisecond
# Save results (image with detections)
if save_img:
if dataset.mode == 'image':
cv2.imwrite(save_path, im0)
else: # 'video' or 'stream'
if vid_path[i] != save_path: # new video
vid_path[i] = save_path
if isinstance(vid_writer[i], cv2.VideoWriter):
vid_writer[i].release() # release previous video writer
if vid_cap: # video
fps = vid_cap.get(cv2.CAP_PROP_FPS)
w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
else: # stream
fps, w, h = 30, im0.shape[1], im0.shape[0]
save_path += '.mp4'
vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
vid_writer[i].write(im0)
if save_txt or save_img:
s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
print(f"Results saved to {save_dir}{s}")
if update:
strip_optimizer(weights) # update model (to fix SourceChangeWarning)
print(f'Done. ({time.time() - t0:.3f}s)')
def parse_opt():
parser = argparse.ArgumentParser()
parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images', help='file/dir/URL/glob, 0 for webcam')
parser.add_argument('--imgsz', '--img', '--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --class 0, or --class 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default='runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
opt = parser.parse_args()
return opt
def main(opt):
print(colorstr('detect: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
check_requirements(exclude=('tensorboard', 'thop'))
run(**vars(opt))
if __name__ == "__main__":
opt = parse_opt()
main(opt)
実行はコマンドプロンプトで行います。(yolov5ディレクトリの中で実行してください)
python detect0.py --source 0 --weight yolov5m.ptpython detect0.py
というのはdetect0.pyというpythonファイルを実行するという意味です。
–source 0
というのは内部カメラを使うということです。
–weight yolov5m.pt
というのはyolov5m.ptという学習モデルを使って物体認識を行うという意味です。
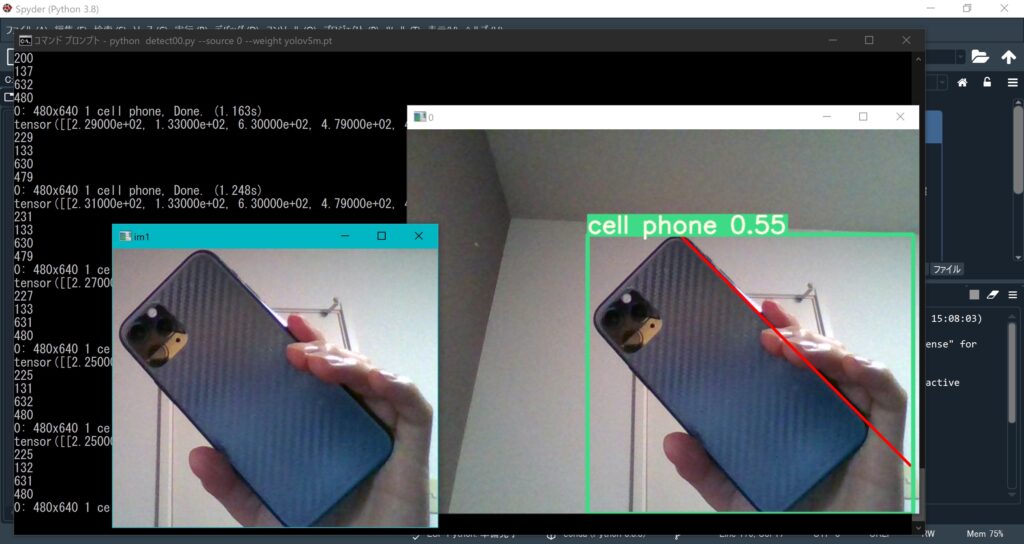
実行結果
実行結果はこんな感じです。
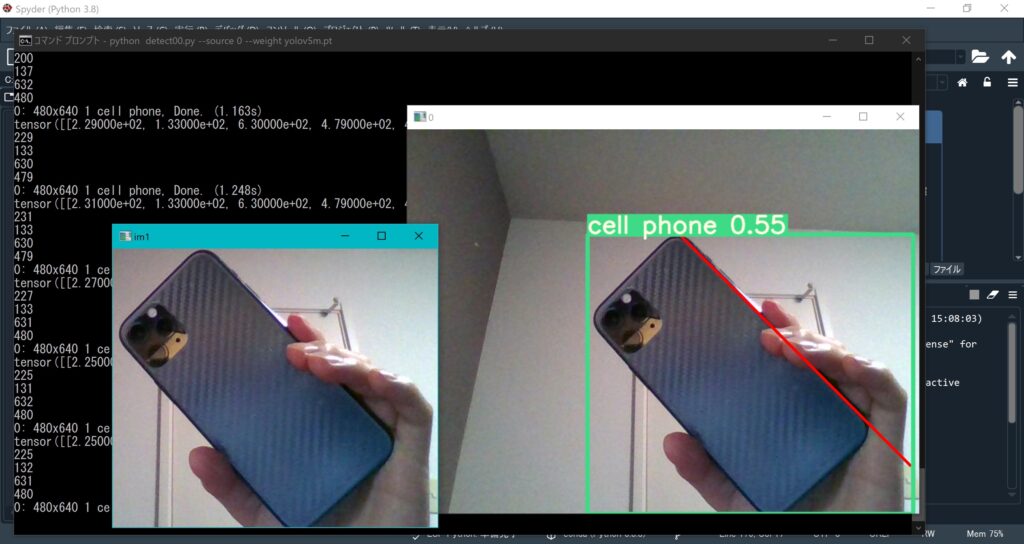
スマホは”cell phone”と認識していますし、スマホのエッジ部が赤線で検出されています。
プログラム解説
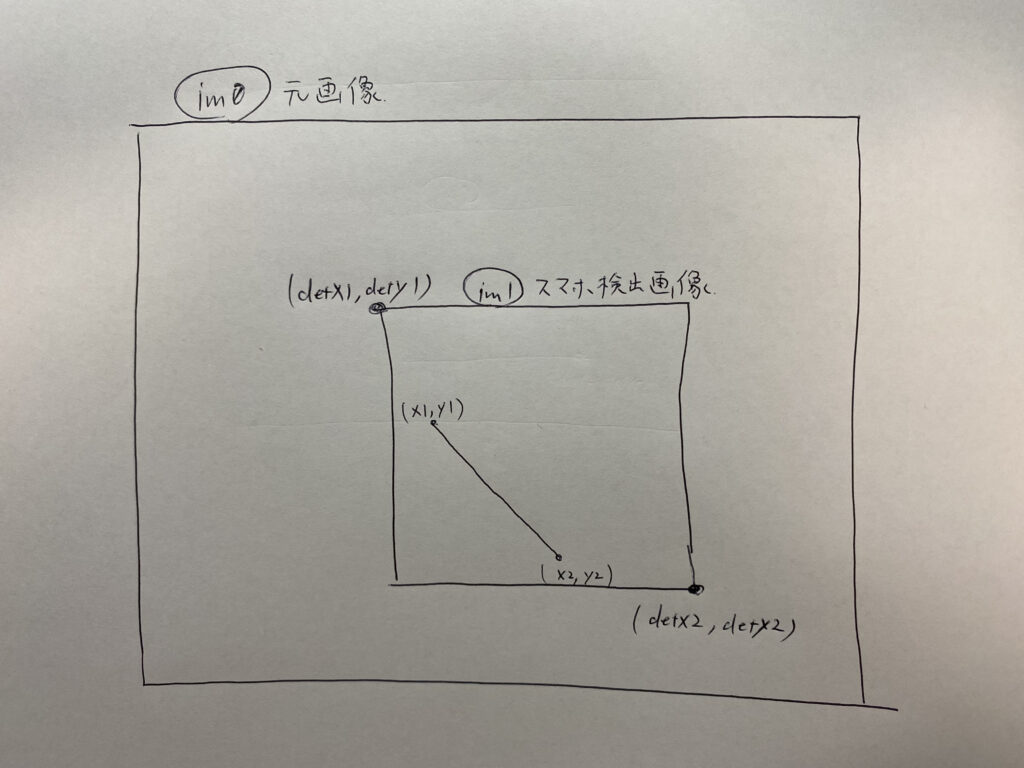
一番重要なのは138行目のdet[ ]です。これに認識した物体の情報が入っています。
具体的には
det[0][0] ← 認識した物体の位置の左上のx(下の画像のdetx1)
det[0][1] ← 認識した物体の位置の左上のy(下の画像のdety1)
det[0][2] ← 認識した物体の位置の右下のx(下の画像のdetx2)
det[0][3] ← 認識した物体の位置の右下のy(下の画像のdety2)
det[0][4] ← 物体の確率
det[0][5] ← 分類したクラス
また、152行目で物体検出した部分のみの画像をim1に入れています。
直線検出はim1の画像から行っています。
もし、直線検出ができない場合は155~157行目のパラメーターをいじってみってください。
まとめ
detect.pyを改造することでYOLOとOpenCVを組み合わせることができました。
まだまだ他にもやれることは沢山ありそうです!
YOLOアルゴリズムの解説はこちら!




コメント